今年年初OpenAI上线的Deep Research开启智能体新阶段,随后其他平台也推出类似服务,同时人们担心其数据隐私安全问题。接着重点介绍了可本地运行的Deep Research,包括其特点、功能以及实际应用示例等内容。

今年年初,OpenAI推出了一项具有重大意义的新功能——Deep Research,这一举措标志着智能体发展迈入了一个全新的阶段。Deep Research就像是一个智能的知识探索者,它能够精准地捕捉用户的需求,然后自主地在广阔的网络海洋中进行信息检索。它不仅仅是简单地收集信息,还能将来自不同源头的多源信息巧妙地整合在一起,再对这些数据进行深度剖析。最终,为用户呈上全面且深入的解答,仿佛一位专业的知识顾问。
此后,Grok 3以及Perplexity等平台纷纷效仿,也推出了类似于Deep Research的服务。一时间,这种强大的智能研究功能在科技领域引起了广泛的关注和惊叹。然而,在大家为Deep Research强大的能力赞叹不已的同时,也不免产生了一些担忧,数据隐私等安全问题成为了人们关注的焦点。毕竟,在信息时代,个人数据的安全至关重要。
不过,现在一个令人振奋的消息传来——可以本地运行的Deep Research诞生了!
我们可以把它看作是一位超级强大的AI研究助手。它的工作原理十分独特,会使用多个大语言模型(LLM)和网络搜索来进行深入且迭代的分析。更值得一提的是,这个系统可以在本地运行,这就好比为用户的数据隐私加上了一把坚固的锁,让用户无需担心数据泄露的风险。当然,如果用户希望进一步增强其功能,也可以选择使用基于云的大语言模型。目前,这个项目已经收获了1.4k的star量,足以证明它的受欢迎程度。
项目地址:https://github.com/LearningCircuit/local-deep-research
该项目具有以下显著特点:
先进的研究功能
它就像一个不知疲倦的研究专家,能够自动开展深度研究工作。在研究过程中,它还会提出一些智能的跟进问题,就像一位严谨的学者不断追问细节,以此确保对主题有全面的理解和深入的挖掘。同时,它会认真追踪引用来源,仔细验证这些来源的可靠性和准确性,就像给信息加上了一层质量保证,确保为用户提供的信息都是可信的。通过多次迭代分析,它能够不断完善研究内容,就像精心雕琢一件艺术品,确保覆盖所有相关方面,不会遗漏任何重要信息。而且,它分析的是整个网页的内容,而不是仅仅提取片段,就像全面了解一个故事而不是只看其中一部分,从而提供更全面、更准确的信息。
对LLM灵活支持
它支持在本地设备上运行AI模型,比如Ollama,这样在数据处理时既高效又能保护隐私,就像把重要的文件放在自己的保险柜里。它还兼容云端大语言模型,像Claude、GPT等,借助云端的强大计算能力和多样化的模型选择,就像拥有了更多的工具来完成任务。它能够无缝集成和使用Langchain框架下的所有模型,用户可以根据自己的具体需求自由选择和配置不同的AI模型,就像根据不同的工作选择合适的工具,从而优化研究效果。
丰富的输出选项
它会为用户提供详细的研究结果,并且会附带引用来源,让用户清楚信息的出处。还能生成内容详实、结构清晰的综合研究报告,就像一份专业的学术论文。同时,它也会提供简洁的摘要,帮助用户快速抓住核心信息,就像给用户提供了一份内容大纲。而且,它会自动追踪信息来源并验证其可靠性,确保用户获取的都是高质量的信息。
增强的搜索集成
它的自动搜索引擎就像一个聪明的筛选器,对于用户正在查询的内容,会进行智能分析,然后根据查询内容选择最合适的搜索引擎。它集成了维基百科,方便用户快速获取准确的事实性知识和百科信息,就像拥有了一本随时可查的百科全书。支持arXiv平台,便于检索和访问最新的科学论文和学术研究成果,让用户紧跟学术前沿。集成PubMed,为生物医学领域的研究人员提供了最新的文献和医学研究资源。支持DuckDuckGo搜索引擎,提供隐私友好的网页搜索体验,虽然可能会受到速率限制,但能保障用户的隐私安全。通过SerpAPI集成,可以获取Google搜索结果,但需要用户提供API密钥。支持Google可编程搜索引擎,允许用户创建个性化的搜索体验,同样需要提供API密钥。集成The Guardian(《卫报》),方便用户获取最新的新闻文章和深度报道,不过也需要提供API密钥。它还支持通过本地RAG搜索对私有文档进行搜索,确保数据隐私,就像在自己的私人图书馆里查找资料。它能够抓取并分析整个网页的内容,提供来源过滤和验证功能,确保搜索结果的可靠性和准确性。用户还可以根据自己的需求自定义搜索参数,优化搜索体验,就像根据自己的喜好调整搜索的方向。
本地文档搜索(RAG)
它基于向量嵌入进行本地文档搜索,就像给文档建立了一个精确的索引。可以为不同主题创建自定义文档集合,方便用户对文档进行分类管理。而且,它非常注重保护用户的隐私,用户的文档会保留在自己的机器上,就像把珍贵的物品放在自己家里。它具有智能分块和检索功能,能够快速准确地找到用户需要的文档。它兼容多种文档格式,如PDF、文本、Markdown等,无论用户的文档是什么格式,它都能轻松处理。还能自动与元搜索集成,实现统一查询,让用户的搜索更加便捷高效。
该项目还配备了一个Web界面(如下所示),为用户提供了更加友好的使用体验。
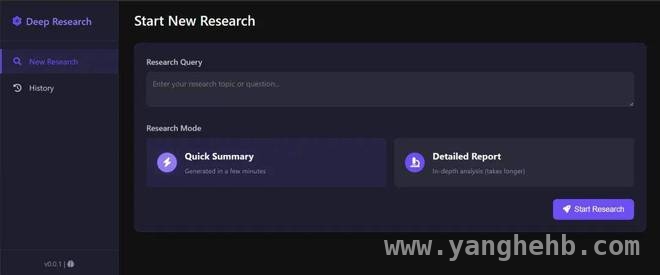
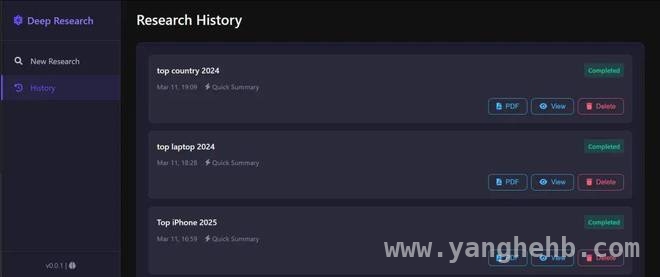
那么,这个项目的实际效果究竟如何呢?我们以官方示例来一探究竟。官方展示了一个关于核聚变能源发展的调查研究。
用户提出问题:“核聚变能源研究的最新进展是什么?商业核聚变什么时候可行?”
然后Deep Research迅速输出了一篇可用的调查报告,内容十分详实。

报告部分截图
完整报告可参考:https://github.com/LearningCircuit/local-deep-research/blob/main/examples/fusion-energy-research-developments.md
通过这个示例,我们可以直观地感受到该项目在深度研究、跨领域分析和信息整合方面具有强大的功能。
如果有小伙伴想要亲自上手体验,只需跟着官方教程进行部署,就能打造属于自己的Deep Research了。
本文先介绍了OpenAI的Deep Research开启智能体新阶段及其他平台的效仿,引出人们对数据隐私的担忧,接着详细阐述了可本地运行的Deep Research的特点、功能和实际应用示例,展示了其在研究方面的强大能力,鼓励用户跟随官方教程体验。
原创文章,作者:Megan,如若转载,请注明出处:https://www.yanghehb.com/324.html

